xxGCC Hierarchical Prefetching Optimization Implementation Analysis
xxGCC Hierarchical Prefetching Optimization Implementation Analysis
20220601~20220701
We now port the hierarchical prefetching optimization feature code into xxGCC830 and evaluate the impact of this optimization on the performance of the generated program.
To achieve code porting, it is necessary to clarify the compiler stage where this optimization is located, and the files involved in that stage. xxGCC830 is based on GCC-8.3.0, so the main focus is on analyzing GCC. The analysis process is seen in the first part, where attention should be paid to the existing types of optimizations in GCC and the naming conventions of the corresponding source code, to prepare theoretically for dealing with other optimization processes in the future.
The evaluation tools are SPEC2006 and SPEC2017, running on servers 6A and 6B, respectively. It is necessary to understand the topics, execution time spans, and reasons for the results of different test sets.
20220701~20220801
We now port the hierarchical prefetching optimization feature code into xxGCC1120 and evaluate the impact of this optimization on the performance of the generated program.
Compared with the porting to xxGCC830, xxGCC1120 is based on GCC-11.2.0, and its files have been added, deleted, and finely adjusted, as detailed in the GCC-maintained ChangeLog-2019 and other records. In addition, the RTL conversion template for prefetching in xxGCC1120 has not been fully ported, thus involving more modified files. For modifications involved in each level of prefetching optimization, please see Appendix A.
1. Hierarchical prefetching optimization in the GCC compilation process
The Middle-End of GCC performs SSA based optimizations on GIMPLE, then converts the GIMPLE to RTL and does more optimizations.——gcc.gnu.org/wiki
The GCC compilation process is divided into three main stages: the FrontEnd, the Middle-End, and the BackEnd. To address the different characteristics of each compilation stage, three types of intermediate representations are generated: Abstract Syntax Tree (AST), GIMPLE, and Register Transfer Language (RTL). Analysis of the source code directories that generate and process these representations can be found in section 1.1.
GCC handles the processing of these intermediate representations by dividing it into passes, where the output of one pass becomes the input for the next pass, as detailed in section 1.2. GIMPLE is optimized through a series of passes in the GCC Middle-End before being handed off to the BackEnd.
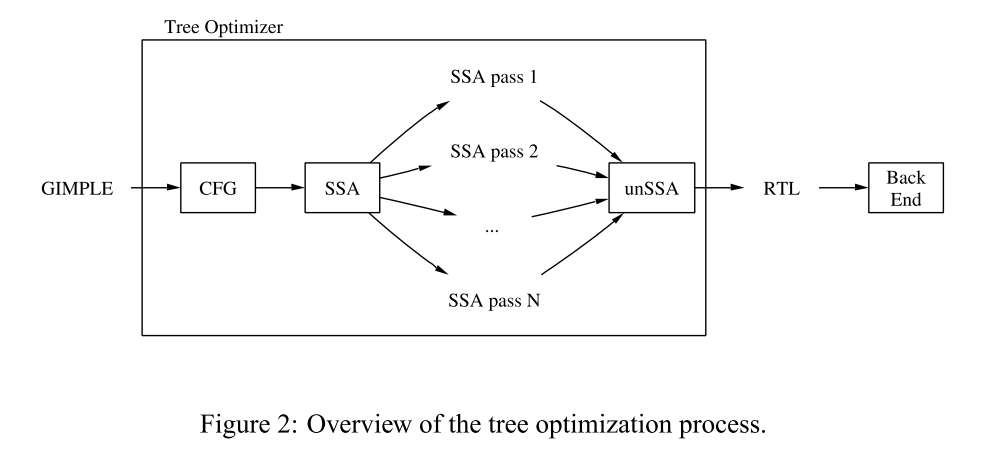
The Middle-End endows GIMPLE with Static Single Assignment (SSA) properties and designs a series of optimization passes based on this feature, collectively referred to as the tree-ssa optimization process. The introduction of tree-ssa is discussed in section 1.3.
GCC introduces prefetching in the loop optimization pass of the tree-ssa process, based on the hierarchical prefetching optimization feature. The relationship between hierarchical prefetching optimization and loop optimization passes is examined in section 1.4.
1.1 Introduction to the GCC Compilation Process and Corresponding Source Code Directories
Legend excerpted from “In-depth Analysis of GCC” pdf-page-30
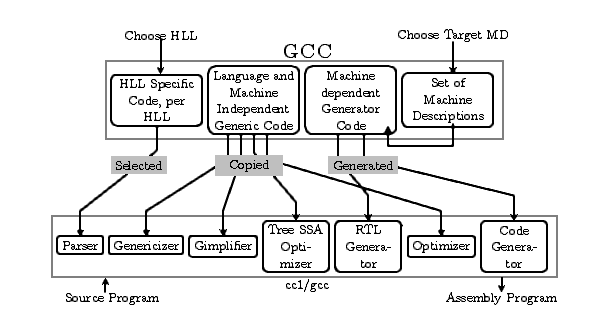
In Figure 3-1, the lower half outlined by the dashed line describes the GCC compilation process and intermediate representations, while the upper half above the dashed line describes the corresponding functionalities in the GCC source code.
In the lower half of the dashed line, cc1 is the compiler executable file generated from compiling the GCC source code. Using gdb to trace the cc1 compilation process allows for debugging of the compiler optimization passes. The following command can be used to locate the current compiler’s cc1 directory:
[zcl@localhost Workshop]$ gcc sum.c -v Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/x86_64-pc-linux-gnu/8.3.0/lto-wrapper Target: x86_64-pc-linux-gnu Configured with: ./configure --disable-multilib Thread model: posix gcc version 8.3.0 (GCC) COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' /usr/local/libexec/gcc/x86_64-pc-linux-gnu/8.3.0/cc1 -quiet -v sum.c -quiet -dumpbase sum.c -mtune=generic -march=x86-64 -auxbase sum -version -o /tmp/ccbNVwAZ.s GNU C17 (GCC) version 8.3.0 (x86_64-pc-linux-gnu) compiled by GNU C version 8.3.0, GMP version 6.1.0, MPFR version 3.1.4, MPC version 1.0.3, isl version isl-0.16.1-GMP
The source code is transformed into assembly code through AST, GIMPLE, and RTL. The directories corresponding to these stages in the GCC source code are as follows:
| Directory*(${GCC-SOURCE} = "gcc-8.3.0/gcc")* | Function*(《In-depth Analysis of GCC》Chp03)* |
|---|---|
\${GCC-SOURCE}/${Language} |
Responsible for generating AST and genericizing it. |
${GCC-SOURCE}/ |
Responsible for generating GIMPLE and RTL. |
\${GCC-SOURCE}/config/${target} |
Stores machine description code, which is referenced during the RTL generation process. |
${GCC-SOURCE}/gen*.[ch] |
Contains generator code related to the target machine. |
Prefetch optimization involves inserting prefetch instructions into the program assembly, specifically by adding calls to the built-in function __builtin_prefetch() in the program’s GIMPLE sequence. During the conversion process from GIMPLE to RTL, the built-in function is transformed into cache control instructions for the target machine based on RTL instruction templates.
1.2 GCC’s divide and conquer strategy — Pass
GCC divides the processing of intermediate representations into passes (Pass), where the output of one pass serves as the input for the next, thereby optimizing the structure of the source code over and over again.
The code responsible for generating GIMPLE and RTL in the mentioned ${GCC-SOURCE}/ directory can generally be organized into GIMPLE optimization passes and RTL optimization passes.
For example, within the GIMPLE optimization passes, there are loop optimization passes located in
tree-ssa-loop.h, tree-ssa-loop.c, tree-ssa-loop-*.c.
There are four types of Passes in GCC: GIMPLE_PASS, RTL_PASS, SIMPLE_IPA_PASS, and IPA_PASS. Different types of Passes are linked together in a linked list, with the pointer named pass.sub.
Under a major Pass category, there are sub-Passes linked in a list, with the pointer named pass.next, as shown in the following diagram example:
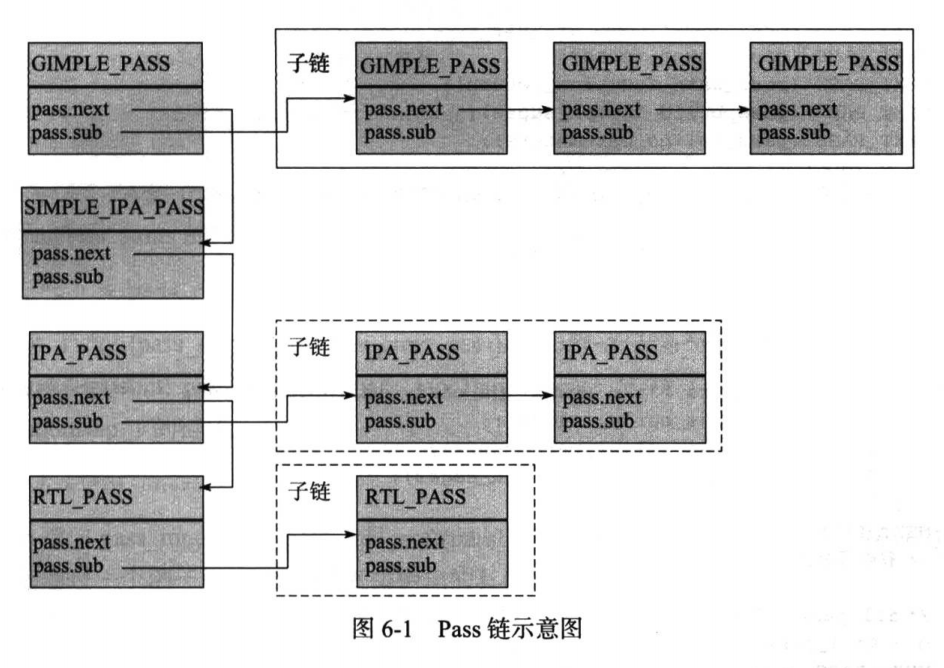
GCC uses three Pass linked lists to store the four types of Passes:
struct opt_pass *all_passesfor GIMPLE and RTL optimizationstruct opt_pass *all_ipa_passesfor IPA optimizationstruct opt_pass *all_lowering_passesfor lowering the GIMPLE sequence
Section 6.2 of “In-depth Analysis of GCC” records the names of all Passes under these three lists. From the paper1, we know that the name of the prefetch optimization pass is “aprefetch”. By reverse engineering the conclusion, one can find a pass called aprefetch in the loop’s subpass within the all_passes chain, which is the prefetch optimization pass. If you want to find the names of other optimization passes, you can use gdb to break execution within an optimization pass, print pass->name, and search the Pass table.
When debugging the prefetch optimization pass, it is necessary to trace the Intermediate Language Tree formed by the optimization passes before and after, to observe whether the prefetch functions and instructions have been correctly inserted. Here are the files that are often focused on:
[zcl@localhost simple_sum]$ gcc sum-ds-demo.c -O2 -fdump-tree-all -fdump-rtl-all -S
[zcl@localhost simple_sum]$ ls -lrt
total 3624
...
-rw-rw-r--. 1 zcl zcl 1088 Jul 15 04:46 sum-ds-demo.c.011t.cfg // To observe the control flow graph and loop information
...
-rw-rw-r--. 1 zcl zcl 1249 Jul 15 04:46 sum-ds-demo.c.164t.cunroll // To observe the input of the prefetch optimization pass
-rw-rw-r--. 1 zcl zcl 27748 Jul 7 23:18 sum-ds-demo.c.167t.aprefetch // To observe the insertion of __builtin_prefetch()
...
-rw-rw-r--. 1 zcl zcl 1204 Jul 15 04:46 sum-ds-demo.c.231t.nrv // To observe the last output of -fdump-tree-all
-rw-rw-r--. 1 zcl zcl 1250 Jul 15 04:46 sum-ds-demo.c.225t.switchlower
-rw-rw-r--. 1 zcl zcl 2186 Jul 15 04:46 sum-ds-demo.c.199t.local-pure-const2
-rw-rw-r--. 1 zcl zcl 1328 Jul 15 04:46 sum-ds-demo.c.198t.uncprop1
-rw-rw-r--. 1 zcl zcl 1195 Jul 15 04:46 sum-ds-demo.c.232t.optimized // The last optimization pass may vary between different versions of GCC
-rw-rw-r--. 1 zcl zcl 5557 Jul 15 04:46 sum-ds-demo.c.234r.expand // Built-in functions are converted to insn based on templates here
...
-rw-rw-r--. 1 zcl zcl 5291 Jul 15 04:46 sum-ds-demo.c.235r.vregs // Note that different prefetches correspond to different insn names, such as second-level prefetch being prefetch_sc_internal; if there's an error corresponding to the Middle-end targetm.code_for_prefetch_sc, it can be checked here
...
1.3 GIMPLE Structure Analysis: Tracing the Introduction of GIMPLE in GCC
At the 2003 GCC Summit, Diego Novillo proposed a simplified three-address code named GIMPLE to be added to the existing intermediate representation. It eliminates the front-end language-specific constructs of the GENERIC tree while also lacking the back-end RTL target machine-specific constructs, facilitating subsequent optimizations.
This involves three new processing stages: Gimplification, construction of control flow graphs, and the SSA module. The original text is as follows:
There are three main components to the basic infrastructure:the gimplifier, the control flow graph (CFG) and the SSA module.2
Section 1.3.1 introduces how these three stages are integrated with the front-end and back-end. Section 1.3.2 describes the characteristics of the intermediate language tree in the Gimplification and SSA module. Section 1.3.3 focuses on the main optimization processes in the Middle-End’s tree-ssa stage.。
1.3.1 Before and After the Introduction of GIMPLE in GCC’s Compilation Process
Each front-end language corresponds to a specific parse tree.
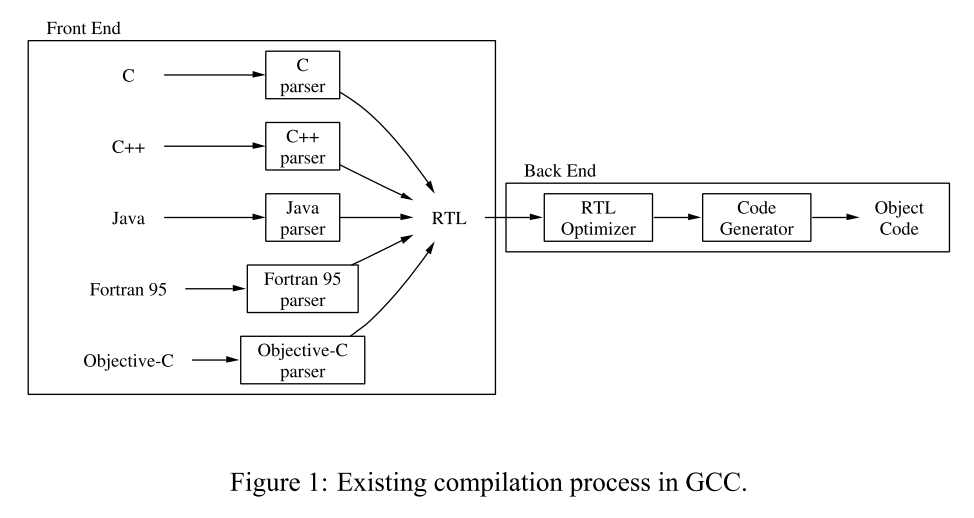
At the 2003 GCC Summit, it was proposed to insert GIMPLE between the parser and RTL, making it independent of front-end languages and back-end machines, as follows:
1.3.2 GIMPLE compensates for the shortcomings of the GCC parse tree.
Observing Figure 1 in section 1.3.1, analyze the deficiencies in GCC’s compilation process before the addition of GIMPLE, and grasp the characteristics of GIMPLE through comparison:
- Lack of a Common Intermediate Representation: In Figure 1, in the front-end, each language generates its own parse tree, making the front-end difficult to extend.
- Side Effects: The parse tree allows for the production of side effects, meaning that understanding the semantics of each front-end language is necessary before optimization can proceed.
- Complex Structure: The parse tree does not possess the three-address characteristic, making optimization challenging when faced with complex expressions.
(e.g.,
if ((a = (b > 5) ? c : d) > 10);)
Gimplification endows the parse tree with three-address characteristics, where three-address means that there can be at most one operator on the right side of the equation, as shown in Figure 4(b).

The SSA module, or Static Single Assignment module, is based on the premise that each variable in the program is assigned exactly once in the program’s code. This is illustrated in Figure 6(b).

1.3.3 The Connection Between GIMPLE and RTL: tree-ssa
According to the paper from the 2003 GCC Summit, the collection of optimizations between GIMPLE and RTL is implemented in the tree-ssa branch.
The GCC official website lists the Tree optimization processes that run after the intermediate language tree has been GIMPLified in tree-ssa, as well as the source files where they are located. For example:
- Array prefetching
This pass issues prefetch instructions for array references inside loops. The pass is located in tree-ssa-loop-prefetch.cc and described by
pass_loop_prefetch.
- Loop optimization
The main driver of the pass is placed in tree-ssa-loop.cc and described by
pass_loop.The optimizations performed by this pass are:
Loop invariant motion. This pass moves only invariants that would be hard to handle on RTL level (function calls, …
1.4 Prefetch optimization is implemented under the loop optimization of tree-ssa.
The scenario addressed by this porting involves loop bodies accessing arrays, where the indices are affine (i.e., linear) functions of the loop indices. A significant portion of data references in scientific code falls into this category. These references have the characteristic that their addresses can be determined in advance, making it possible to prefetch these locations. 3
When evaluating with the SPEC benchmark, the performance improvement brought by prefetch optimization varies among different problems. For example, one of the integer benchmarks in SPEC2006, number 429, involves the simplex method, where prefetching has shown a noticeable performance improvement in tests. A detailed analysis of the problem content can confirm the core functions and segments. (TODO)
2. Hierarchical Data Prefetching and C3B Instruction Set Support
In GCC, level-one prefetching has been implemented, but it has limitations, as analyzed in Section 2.1. Therefore, xxGCC830 introduced three levels of prefetching and prefetch control, based on the hardware foundation described in Section 2.2. xxGCC830 allows control over the prefetching level through compiler options, with modifications to the involved files further explained in Section 2.3. In Section 4, the performance of hierarchical prefetching will be evaluated to verify the effectiveness of this method.
Section 2.3 includes additional information about the syntax of the opt files related to xxGCC, which should be noted.
2.1 Hierarchical Data Prefetching Concept
Data prefetching is a technique to reduce storage latency, overlapping memory access with computation to hide memory access delays and improve memory access performance. Prefetching is based on utilizing the idle bandwidth of the memory system. The aim of data prefetching is to move data in advance from storage levels far from the processor closer to the processor, thereby reducing the memory access latency when the data is used. Prefetching operations and the processor’s computation process occur concurrently, with the storage system fetching data from the main memory to the cache a certain number of clock cycles in advance.1
The farther from the CPU, the lower the cost to increase bandwidth, and the greater the bandwidth. By prefetching most of the content in advance to the larger storage areas of L2 and L3, which are farther from the CPU, the prefetching distance to L1 can be shortened. (timeiter/latencyL1+L2+L3 —> timeiter/latencyL1), allowing the CPU to execute in parallel with memory access.
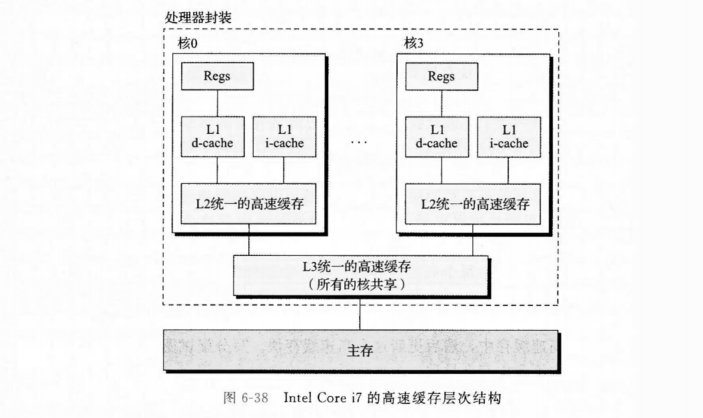
Excerpted from “Computer Systems: A Programmer’s Perspective”
2.2 Operations of the C3B Instruction Set Regarding Hierarchical Caching
Located in Section 4.8 Cache Control Instructions of the Core3B Core Architecture Manual, it provides control instructions for multiple layers of the cache, with prefetch locations controlled by software. The table below is outdated; please refer to Appendix A for an explanation of the backend instruction templates to understand the actual instructions inserted.
| Layer | Instrument | mnemonic | expansion (not verbatim) |
|---|---|---|---|
| L1 | FLDS | FILLDE | fill_dirty_exclusive |
| FLDD | FILLDE_E | fill_dirty_exclusive_eliminated | |
| LDWE | FILLCS | fill_clean_share | |
| L2 | LDW | S_FILLCS | second_fill_clean_share |
| LDL | S_FILLDE | second_fill_dirty_exclusive | |
| External Cache | LDDE | FILLCS_E | fill_clean_share_exokernel |
| VLDS | E_FILLDE | exokernel_fill_dirty_exclusive |
When the structure of the example program being compiled is relatively complex, embedded assembly can be added before and after the statements you want to locate in the assembly:
asm(“################################################”);
2.3 xxGCC830 Optimization Levels and Option Controls
The GCC official website explains the options enabled at different optimization levels from -O0 to -Os for various versions of GCC. In GCC 8.3.0, it is indicated that:
- At the -O2 optimization level, GCC performs almost all optimizations that do not involve a trade-off between space and time.
- At the -Os optimization level, which is aimed at optimizing for size, GCC explicitly disables -fprefetch-loop-arrays.
Through practice, by comparing the assembly files obtained before and after adding -fno-prefetch-loop-arrays under -O2, it can be verified that -O2 enables -fprefetch-loop-arrays.
SWGCC830 introduces hierarchical prefetch control options by modifying gcc-8.3.0/gcc/config/sw_64.sw_64.opt, with the convention that level one prefetching is enabled by default, and other prefetch controls are disabled by default.
| Option | Meaning | Flags in the source code | Initial flag values |
|---|---|---|---|
| -fxx-prefetch-dc | enables L1 prefetching | flag_xx_prefetch_dc | 1 |
| -fxx-prefetch-sc | enables L2 prefetching | flag_xx_prefetch_sc | 0 |
| -fxx-prefetch-tc | enables L3 prefetching | flag_xx_prefetch_tc | 0 |
| -fxx-multi-prefetch-control | enables multi-level prefetch control | flag_xx_multi_preftch_control | 0 |
Using options with the -fsw prefix will set the flag to 1. GCC automatically generates corresponding options with the -fno- prefix for these -f prefixed options, used to set the flag to 0.
| Option | Meaning | Flags in the source code |
|---|---|---|
| -fno-sw-prefetch-dc | disables L1 prefetching | flag_sw_prefetch_dc |
| -fno-sw-prefetch-sc | disables L2 prefetching | flag_sw_prefetch_sc |
| -fno-sw-prefetch-tc | disables L3 prefetching | flag_sw_prefetch_tc |
| -fno-sw-multi-prefetch-control | disables multi-level prefetch control | flag_sw_multi_preftch_control |
Note: When editing the xxGCC830’s opt file, ensure consistency in syntax and context. For example, the keyword used to declare flags in GCC830 is Target Report Var, while in GCC1120, it is Target Var. If not written according to the syntax, you will encounter an error where option.o cannot be compiled during GCC compilation.
3. xxGCC830 Prefetch Algorithm Process
To observe the adjustments made by the compiler to the program structure during the optimization process, this section uses sum-*.c as an example. Through the GCC built-in option -fdump-tree-all, the output of the optimization passes is printed, observing the input for the prefetch optimization pass. Section 3.1 will first introduce the intermediate representation structure of function bodies in GCC, and the algorithm execution process is shown in Section 3.2. Appendix A will summarize the incremental modifications made to the GCC source code by each layer of prefetch optimization in xxGCC.
3.1 Important Data Structures
For sum-ds-demo.c, by compiling with the -fdump-tree-all option, the intermediate language trees from different processing stages (see 1.2 or 1.3.3) will be output to files, with filenames suffixed by the name of the processing stage. By observing the output time of the intermediate language trees, it can be seen that the pass before the aprefetch pass is named cunroll, whose output will serve as the input for the prefetch optimization pass. In cunroll, the compiler has already represented the main function with basic blocks composed of gimple statements and divided the loop.
In Section 3.1, the source code excerpts of data structure definitions only list the member variables involved in the algorithm in Section 3.2.
3.1.1 sum-ds-demo.c
Using sum-ds-demo.c as an example to show the compiler’s representation of the intermediate syntax tree.
/* gcc sum-ds-demo.c -O2 -fdump-tree-all */
#include<stdio.h>
#ifndef MAX_NUM
#define MAX_NUM 1024*1024
#endif
int sum = 0;
int main(){
int num[MAX_NUM];
// The size of array should be bigger than L3 cache, or the array will remain in the cache after initialization.
for(int i=0;i<MAX_NUM;i++)
num[i] = i;
for(int i=0;i<MAX_NUM;i++)
sum += num[i];
printf("The sum of array num[] is %d" ,sum);
return 0;
}
3.1.2 Representing the Function Body with Basic Blocks and GIMPLE Statements
A Basic Block can only be entered from its first three-address code and exited from its last three-address code. GCC makes it known the addresses of the preceding and following basic blocks (bb), as well as the entry point of the chain of gimple statements it contains.
A GIMPLE statement is a three-address code, where the right-hand side of the three-address code has at most one operator. GCC makes it known the number of operators it contains, the basic block (bb) it belongs to, and the addresses of the preceding and following GIMPLE statements. This is linked by pointers in the source code such as prev and next.
/* gcc/basic-block.h */
struct GTY((chain_next ("%h.next_bb"), chain_prev ("%h.prev_bb"))) basic_block_def {
/* Previous and next blocks in the chain. */
basic_block prev_bb;
basic_block next_bb;
/* To view the GIMPLE statement information contained in a basic block, use `bb->il->gimple`. */
union basic_block_il_dependent {
struct gimple_bb_info GTY ((tag ("0"))) gimple;
struct {
rtx_insn *head_;
struct rtl_bb_info * rtl;
} GTY ((tag ("1"))) x;
} GTY ((desc ("((%1.flags & BB_RTL) != 0)"))) il;
}
/* gcc/gimple.h */
struct GTY((desc ("gimple_statement_structure (&%h)"), tag ("GSS_BASE"), chain_next ("%h.next"), variable_size)) gimple{
/* Number of operands in this tuple. */
unsigned num_ops;
/* [ WORD 3 ] Basic block holding this statement. */
basic_block bb;
/* [ WORD 4-5 ]
Linked lists of gimple statements. The next pointers form
a NULL terminated list, the prev pointers are a cyclic list.
A gimple statement is hence also a double-ended list of
statements, with the pointer itself being the first element,
and the prev pointer being the last. */
gimple *next;
gimple *GTY((skip)) prev;
};
The following figure shows the intermediate language tree formed by sum-ds-demo.c, where <bb 3~4> represents the initialization loop body for the num array in the main function, and <bb 5~6> represents the loop in the main function that sums the num array.
<bb 2~6> is executed in numerical order by default. If a goto statement is encountered, it jumps according to the marked probability distribution.
The probabilities [98.99%] and [1.01%] marked for jumps within <bb 3> are calculated based on the actual execution statistics.
The reason i_10 is defined in <bb 3> instead of directly using i_21 is due to the definition of Static Single Assignment (SSA).
The PHI function noted in <bb 3> comments is a selection function defined by SSA for merging branches. Although this PHI function is commented out in the dump file, it is meaningful and executed before <gimple_seq 0> in actual execution. In i_21 = PHI<0(2), i_10(8)>, the first parameter of the PHI function, 0, represents the constant 0, and the second parameter, i_10, represents a variable, with the numbers in parentheses, 2 and 8, indicating that 0 comes from <bb 2> and i_10 comes from <bb 8>.
<bb 6> is listed separately to show the connection between GIMPLE statements within the basic block.
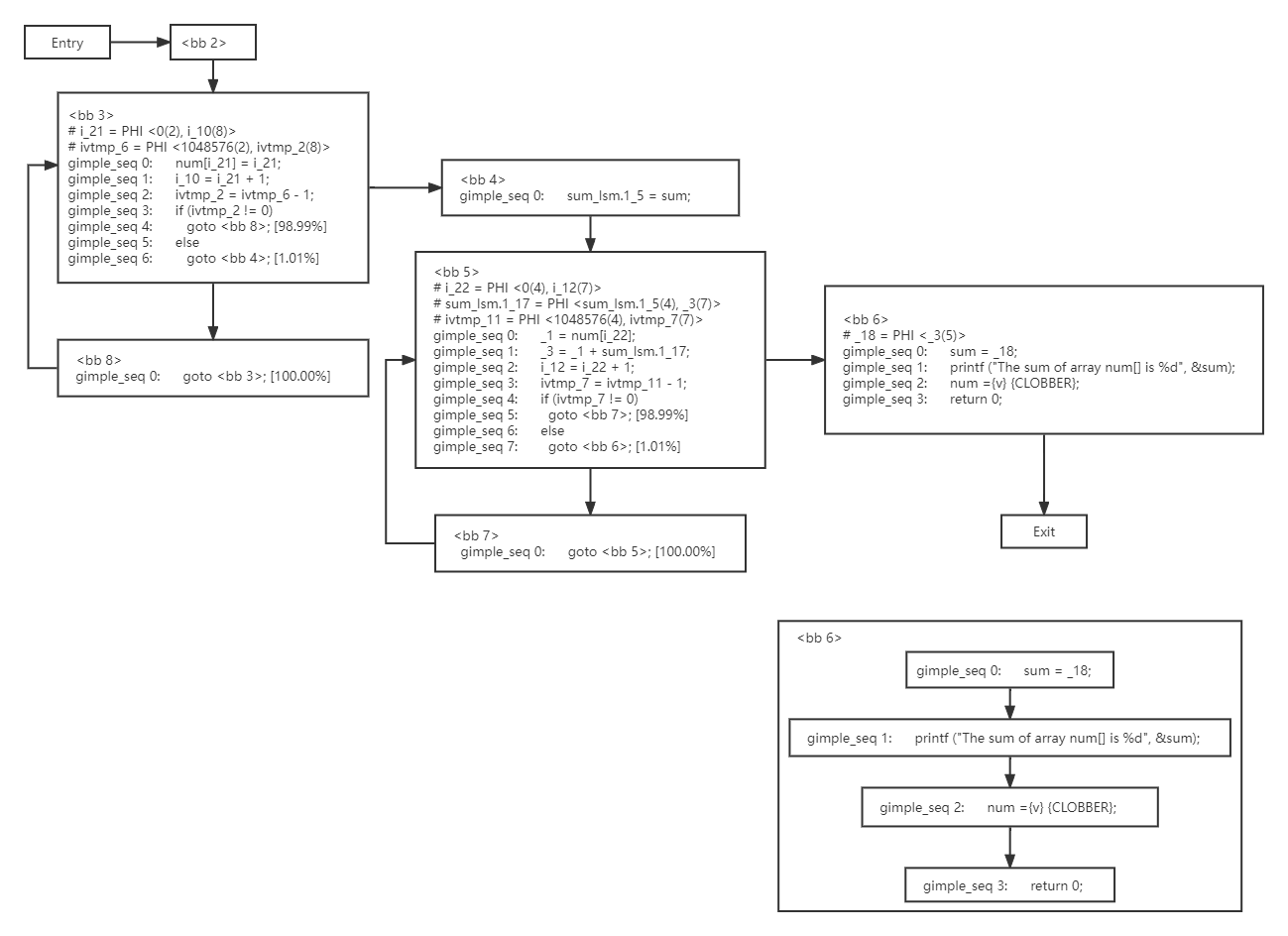
3.1.3 Summarization and Splitting of Loops in GIMPLE
In this section, we first introduce the definition of Loops by GCC, then analyze the sum-ds-demo.c.011t.cfg file output by -fdump-tree-all, and finally introduce the member variables involved in the algorithm in Section 3.2.
A Loop is defined by a header and a latch, where the header is the entry block of the loop, and the latch points from within the loop back to the header. The body of the loop is the set of blocks that are reachable from the latch in the reverse direction of the edges in the CFG and are dominated by its header.
In the following situations, a loop will be split, though such instances have not been encountered yet. (TODO)
Loops with several latches may appear if several loops share a single header, or if there is branching in the middle of the loop. However, the representation of loops in GCC allows only loops with a single latch. During loop analysis, headers of such loops are split and forwarder blocks are created to disambiguate their structures.
The distribution of basic blocks in sum-ds-demo.c.165t.cunroll was analyzed in the previous section. Since optimizations in passes before cunroll deleted some Loop information contained in the intermediate language tree, this section will analyze sum-ds-demo.c.011t.cfg. From the following quote, GCC designates the root node of the loop tree as a fake loop, as seen in the example below.
Body of the loop is the set of blocks that are dominated by its header, and reachable from its latch against the direction of edges in CFG. The loops are organized in a containment hierarchy (tree) such that all the loops immediately contained inside loop L are the children of L in the tree. This tree is represented by the
struct loopsstructure. The root of this tree is a fake loop that contains all blocks in the function. Each loop is represented in astruct loopstructure. Each loop is assigned an index (numfield of thestruct loopstructure), and the pointer to the loop is stored in the corresponding field of thelarrayvector in the loops structure. The indices do not have to be continuous; there may be empty (NULL) entries in thelarraycreated by deleting loops. Also, there is no guarantee on the relative order of a loop and its subloops in the numbering. The index of a loop never changes.
All loops in a Function are organized in a tree-like data structure named loops. The root node of the loops tree is a fake loop that contains all basic blocks, as shown in the Loop 0 in the code snippet below. In sum-ds-demo.c, there are two loops; the first loop, Loop 1, initializes the num array, and the second loop, Loop 2, accumulates the num array. The numbers after header and latch are the basic block numbers, outer is the Loop number of the outer loop, and nodes record the block numbers contained in the loop body.
;; Function main (main, funcdef_no=11, decl_uid=1981, cgraph_uid=11, symbol_order=12)
Removing basic block 10
Merging blocks 8 and 9
Merging blocks 8 and 11
;; 3 loops found
;;
;; Loop 0
;; header 0, latch 1
;; depth 0, outer -1
;; nodes: 0 1 2 3 4 5 6 7 8
;;
;; Loop 2
;; header 7, latch 6
;; depth 1, outer 0
;; nodes: 7 6
;;
;; Loop 1
;; header 4, latch 3
;; depth 1, outer 0
;; nodes: 4 3
;; 2 succs { 4 }
;; 3 succs { 4 }
;; 4 succs { 3 5 }
;; 5 succs { 7 }
;; 6 succs { 7 }
;; 7 succs { 6 8 }
;; 8 succs { 1 }
/* succs meaning:succeeds */
main ()
{
int i;
int i;
int num[1048576];
int D.1993;
<bb 2> :
i = 0;
goto <bb 4>; [INV]
<bb 3> :
num[i] = i;
i = i + 1;
<bb 4> :
if (i <= 1048575)
goto <bb 3>; [INV]
else
goto <bb 5>; [INV]
<bb 5> :
i = 0;
goto <bb 7>; [INV]
<bb 6> :
_1 = num[i];
sum.0_2 = sum;
_3 = _1 + sum.0_2;
sum = _3;
i = i + 1;
<bb 7> :
if (i <= 1048575)
goto <bb 6>; [INV]
else
goto <bb 8>; [INV]
<bb 8> :
printf ("The sum of array num[] is %d", &sum);
D.1993 = 0;
num = {CLOBBER};
return D.1993;
}
The function maintains the loops, and the container vector within loops maintains each loop. Each loop is aware of the information about its outer and inner loop bodies.
/* gcc/function.h */
struct GTY(()) function{
/* The exception status for each function. Exception Handling(EH) */
struct eh_status *eh;
/* The loops in this function. */
struct loops *x_current_loops;
...
}
/* gcc/cfgloop.h */
308: struct GTY(()) loops{
/* Arrays f the loops. */
vec<loop_p, va_gc> *larray;
/* Pointer to root of loop hierarchy tree. */
struct loop *tree_root;
}
116: struct GTY((chain_next ("%h.next"))) loop{
int num;
/* Superloops of the loop, starting with the outermost loop. */
vec<loop_p, va_gc> *superloops;
/* The first inner (child) loop or NULL if innermost loop. */
struct loop *inner.
/* Link to the next (sibling) loop. */
struct loop *next.
}
3.1.4 Organization of Ref in GIMPLE Statements for Lvalues and Rvalues in Memory Access
The scenario for the prefetch optimization pass is focused on loop bodies, particularly on the memory access points within these loop bodies. GCC represents a memory access point (reference) in a loop body using the following abstract model. a[i] is a memory access point located in the right-hand side (rhs) of a GIMPLE_ASSIGN type GIMPLE statement:
/* ref = base + step * iter + delta */
for (i=m; i<n; i+=r)
sum += a[i];
In the actual algorithm, the collected memory access point information and their meanings are as follows:
| Memory Access Information | Meaning | Assignment |
|---|---|---|
| base | Array base address | &a[0] |
| step | Iteration step, related to data type and iterator increment | sizeof(a[i]) * r |
| delta | Array offset constant, related to data type and iterator initial value | sizeof(a[i]) * m |
GCC uses the data structure mem_ref to record memory access point information, and mem_ref_group to summarize memory access points that have the same base and step. The mem_ref_group->next connects memory access groups arranged in descending order by step, as detailed in Section 3.2 in the analysis of the function gather_memory_references.
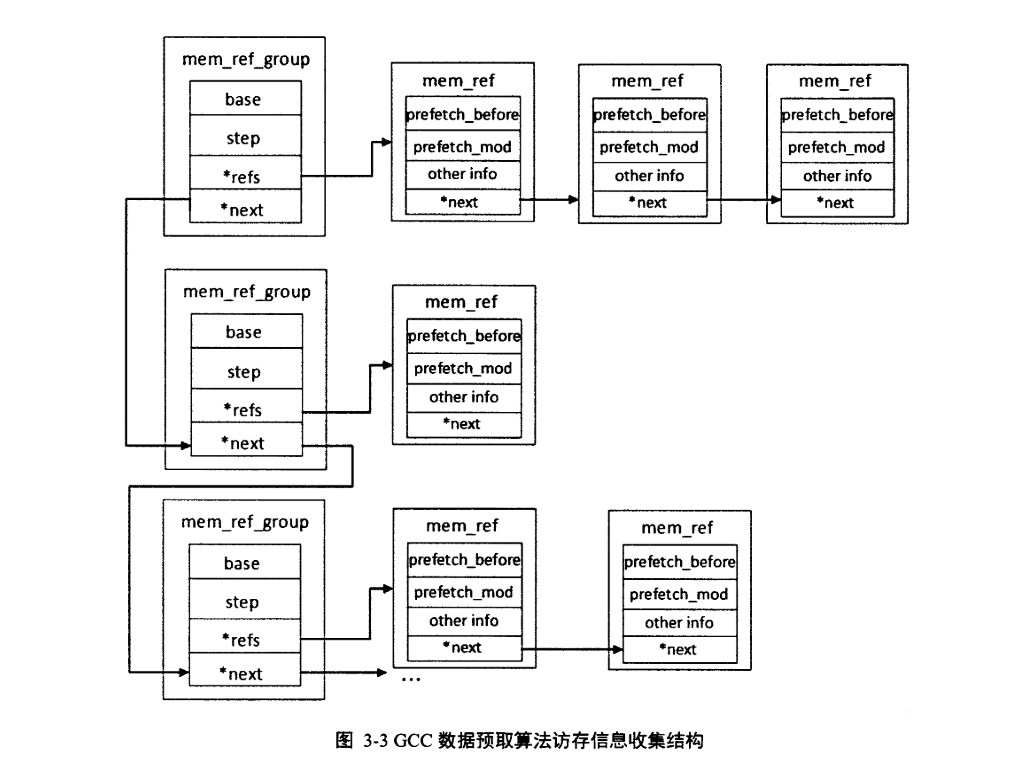
Given the following example, you will find it consistent with the table provided above:
for (int i=9; i<MAX_NUM; i+=7)
sum += a[i]
(gdb) p *refs
$12 = {base = 0x7ffff66f2cb0, step = 0x7ffff6727918, refs = 0x1544320, next = 0x0, uid = 1}
(gdb) p int_cst_value(refs->step)
$13 = 28
(gdb) p *refs->refs
$11 = {stmt = 0x7ffff6716960, mem = 0x7ffff66f27a8, delta = 36, group = 0x16f1c40, prefetch_mod = 1, prefetch_before = 18446744073709551615, reuse_distance = 0, next = 0x154b210, uid = 1, write_p = 0, independent_p = 0,
issue_prefetch_p = 0, storent_p = 0}
(gdb) p refs->refs->delta
$15 = 36
The following lists the important member variables. Section 3.2 will expand on the corresponding algorithm locations, providing examples for easier gdb debugging:
/* gcc/tree-ssa-loop-prefetch.c */
struct mem_ref_group
{
/* For the same array[MAX_NUM], forward and reverse accesses are considered as two mem_ref_groups
* base are &array[0] and &array[MAX_NUM], respectively, with step being positive or negative
*/
tree base;
/* Its assignment is located in gather_memory_reference, different from the iv.step
* in the function idx_analyze_ref called during the process
* mem_ref_group->step = array_ref_element_size (base) * iv.step
*/
tree step;
struct mem_ref *refs;
struct mem_ref_group *next;
};
struct mem_ref
{
/* Similar to step, delta = array_ref_element_size (base) * idelta */
HOST_WIDE_INT delta;
/* See examples in Appendix B given by the official GCC */
unsigned HOST_WIDE_INT prefetch_mod;
/* In some examples, even if the memory access point mem_ref is collected, it may be determined in the function prune_by_reuse that it does not generate prefetch */
unsigned HOST_WIDE_INT prefetch_before;
struct mem_ref *next;
/* In the function schedule_prefetches, existing prefetch slot resources are allocated, deciding whether to prefetch */
unsigned issue_prefetch_p : 1;
};
During gdb debugging, it will be found that some function parameters are passed as tree-node pointers pointing to mem_ref_group and mem_ref type data. At this point, you should perform a cast based on your understanding of the algorithm. Or, get a hint through TREE_CODE (*addr_p)=ARRAY_REF before performing the cast:
(gdb) p *addr_p
$19 = (tree) 0x7ffff66f2cb0
(gdb) p **addr_p
$20 = {
base = {
code = ARRAY_REF,
side_effects_flag = 0,
constant_flag = 0,
addressable_flag = 0,
volatile_flag = 0,
readonly_flag = 0,
--Type <RET> for more, q to quit, c to continue without paging--q
Quit
(gdb) p *(mem_ref*)addr_p
$21 = {
stmt = 0x7ffff66f2cb0,
mem = 0x0,
delta = 0,
group = 0x7ffff65c2780,
prefetch_mod = 140737328015712,
prefetch_before = 140737488345200,
reuse_distance = 4294957176,
Introduction to ARRAY_REF could be found at official site of GCC:
ARRAY_REF
These nodes represent array accesses. The first operand is the array; the second is the index. To calculate the address of the memory accessed, you must scale the index by the size of the type of the array elements. The type of these expressions must be the type of a component of the array. The third and fourth operands are used after gimplification to represent the lower bound and component size but should not be used directly; call
array_ref_low_boundandarray_ref_element_sizeinstead.
3.2 Prefetch Algorithm
The GCC official documentation on the algorithm content can be found in Appendix B. A brief summary: The prefetch algorithm aims to calculate memory access locations, assess whether the benefits of memory access outweigh the costs, compute prefetch locations, decide which memory access points to allocate prefetch resources to, unroll loops, and issue prefetch instructions.
3.2.1 Common Entry for Pass
The optimization operation interface for the intermediate language tree by Pass is Pass->execute(), with execute_one_pass dynamically binding to different Pass implementations during runtime. The prefetch pass named aprefetch is defined in tree-ssa-loop-prefetch.c, and gdb can be used to enter the corresponding execution function. The following code only lists key statements and is somewhat simplified.
/* gcc/passes.c */
execute_one_pass (opt_pass *pass)
/* (gdb)b if $_streq(pass->name, "aprefetch") */
todo_after = pass->execute (cfun)
3.2.2 Common Entry for Loops
To facilitate debugging of cc1 during the GCC compilation process, replace all -g options with -g3 in the Makefile under the gcc_build folder, and then execute make -j && make install to print macros during the process.
/* gcc/tree-ssa-loop-prefetch.c */
pass_loop_prefetch::execute (function *fun)
{
/* Calculate the length of vector *x_current_loops in cfun, which holds all loops, <=1 excludes fake loops */
if (number_of_loops (fun) <= 1)
return 0;
/* By default, defined as the size of L1_CACHE_LINE_SIZE, can be defined externally via option */
if ((PREFETCH_BLOCK & (PREFETCH_BLOCK - 1)) != 0)
return 0;
return tree_ssa_prefetch_arrays ();
}
tree_ssa_prefetch_arrays (void)
{
/* Check if the target machine (targetm) supports prefetching */
if (!targetm.have_prefetch () || PREFETCH_BLOCK == 0)
return 0;
/* Ensure the existence of the builtin function __builtin_prefetch, SC for L2, TC for L1, SWGCC added checks for prefetch support on these two levels
* From the following paper, when GIMPLE statements are converted to RTL statements, __builtin_prefetch is replaced according to the backend instruction template
* (2014). Application and optimization of GCC data prefetch technology for UniCore-3 processors.
*/
#ifndef SW_MULTI
if (!builtin_decl_explicit_p (BUILT_IN_PREFETCH))
if (!builtin_decl_explicit_p (BUILT_IN_PREFETCH_SC))
if (!builtin_decl_explicit_p (BUILT_IN_PREFETCH_TC))
set_builtin_decl;
#else
if (!builtin_decl_explicit_p (BUILT_IN_PREFETCH))
set_builtin_decl;
#endif
/* Retrieve the loop pointer from the global variable cfun, the retrieval order is controlled by flag=LI_FROM_INNERMOST, its meaning is as follows
* Iterate over the loops in the reverse order, starting from innermost ones.
*/
FOR_EACH_LOOP (loop, LI_FROM_INNERMOST)
unrolled |= loop_prefetch_arrays (loop);
}
3.2.3 Loop Prefetch Algorithm
Prefetch instructions are issued only under rather specific conditions, which often leads to the failure of designing test cases. The next section lists the situations currently encountered where memory is accessed but prefetch instructions are not issued, for reference.
No Prefetch for Loops with Few Executions
Loop nesting will be checked; the optimize_loop_nest_for_size_p function performs a depth-first traversal of the current loop’s subloops, in the order shown in the following diagram. If the loop pointed to by the pointer cfun within the function body is not executed (NODE_FREQUENCY_UNLIKELY_EXECUTED), or the execution count of loop->header is less than a certain value (NODE_FREQUENCY_EXECUTED_ONCE |
NODE_FREQUENCY_UNLIKELY_EXECUTED), then the performance improvement brought by prefetching is minimal, and prefetching is not performed. |
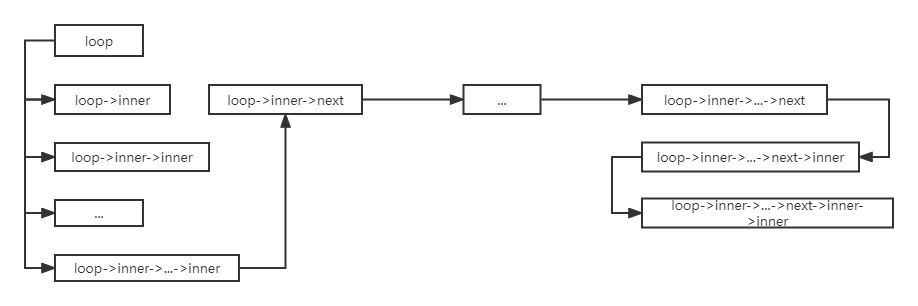
/* gcc/tree-ssa-loop-prefetch.c */
loop_prefetch_arrays (struct loop *loop)
/* Depth-first traversal of a loop's subloops; if the function body containing the loop is unlikely to be executed, or the loop's iteration count is below a certain threshold, prefetching is not performed.*/
if (optimize_loop_nest_for_size_p (loop))
return false;
Calculating time, ahead, estniter
When introducing the Loop data structure in Section 3.1, it was noted that the loop body Loop’s basic block numbers are recorded in loop-in-loop.c.011t.cfg. Taking the control flow graph of a program loop-in-loop.c with a double-layer for loop as an example, this part introduces the meanings of time, ahead, and estniter.
#ifndef MAX_NUM
#define MAX_NUM 1024*1024
#endif
int sum = 0;
int main(){
for (int i=0;i<MAX_NUM;i++){
for (int j=0;j<MAX_NUM;j++){
sum += j;
}
}
return 0;
}
;; 3 loops found
;;
;; Loop 0
;; header 0, latch 1
;; depth 0, outer -1
;; nodes: 0 1 2 3 4 5 6 7 8
;;
;; Loop 1
;; header 7, latch 6
;; depth 1, outer 0
;; nodes: 7 6 5 3 4
;;
;; Loop 2
;; header 5, latch 4
;; depth 2, outer 1
;; nodes: 5 4
;; 2 succs { 7 }
;; 3 succs { 5 }
;; 4 succs { 5 }
;; 5 succs { 4 6 }
;; 6 succs { 7 }
;; 7 succs { 3 8 }
;; 8 succs { 1 }
time is an estimated value of the execution time of the function body. The function tree_num_loop_insns traverses each GIMPLE statement in every basic block (bb) within the loop body, calculating their weighted sum as the estimated time time required for one iteration of the loop body. In the example above, Loop 1 contains five basic blocks, and Loop 2 contains two, not considering the number of iterations of the subloop Loop 2 within Loop 1. (TODO: Provide specific values)
/* In gdb, print the weights corresponding to different GIMPLE stmt types as follows:
* $eni_time_weights = {call_cost = 10, indirect_call_cost = 15,
target_builtin_call_cost = 1, div_mod_cost = 10, omp_cost = 40, tm_cost = 40,
return_cost = 2, time_based = true}
*/
time = tree_num_loop_insns (loop, &eni_time_weights);
if (time == 0)
return false;
ahead is the prefetch lead distance, the number of iterations ahead of the current execution point where prefetching should occur. Its value is the ceiling of the ratio of the memory access latency PREFETCH_LATENCY to the single iteration delay time of the loop. PREFETCH_LATENCY is read from the command line, and there are differences in the implementation between GCC 8.3.0 and GCC 11.2.0, as seen in Appendix A.
/* If accessing sum[i] requires 5 clock cycles, and one iteration of the loop takes 2 clock cycles, then prefetching 3 iterations ahead is done, with `ahead=3`.
*/
ahead = (PREFETCH_LATENCY + time - 1) / time;
est_niter is the total number of iterations for the loop. Diving into the function estimated_stmt_executions_int at its deepest call, it calculates the estimated number of executions of the latch of the LOOP, focusing on Loop->latch, as detailed in Section 3.1 on the explanation of loop bodies. If this estimated value cannot be derived or exceeds the upper limit, estimated_stmt_executions_int sets est_niter to -1. In this case, likely_max_stmt_executions_int will make est_niter equal to loop->any_likely_upper_bound.
est_niter = estimated_stmt_executions_int (loop);
if (est_niter == -1)
est_niter = likely_max_stmt_executions_int (loop);
Cost Model 1: Iteration Lookahead Distance: Total Number of Iterations in the Loop
According to the paper1 or the comments at the beginning of tree-ssa-loop-prefetch.c (see Appendix B), Cost Model 1 calculates the ratio of the total number of iterations in the loop est_niter to the iteration lookahead distance ahead. The preset lower limit for the ratio, TRIP_COUNT_TO_AHEAD_RATIO, is 4, and prefetching is not performed if the ratio is below this value.
/* no prefetching when est_niter < TRIP_COUNT_TO_AHEAD_RATIO * ahead
* For example, if `sum[i]` needs to be prefetched 2 iterations ahead, but the for-loop only iterates 3 times, then `3 < 4 * 2`. In this case, prefetching is not cost-effective.
*/
if (trip_count_to_ahead_ratio_too_small_p (ahead, est_niter))
return false;
Calculate ninsns
The calculation of the estimated number of instructions in the loop body, ninsns, follows the same method as the calculation for time, with the only difference being in the setting of the weights.
/* gdb shows the weights as follows
* $eni_size_weights = {call_cost = 1, indirect_call_cost = 3,
target_builtin_call_cost = 1, div_mod_cost = 1, omp_cost = 40, tm_cost = 10,
return_cost = 1, time_based = false};
*/
if (flag_sw_multi_prefetch_control)
basic_index_ninsns_refs_head = new struct;
ninsns = tree_num_loop_insns_modify (loop, &eni_size_weights, basic_index_ninsns_refs_head);
else
ninsns = tree_num_loop_insns (loop, &eni_size_weights);
xxGCC implements multi-level prefetch control optimization here. The definition and assignment of flag_sw_multi_prefetch_control, as well as the explanation of multi-level optimization control, can be found in Appendix A. basic_index_ninsns_refs_head points to a linked list that records the index of all basic blocks (bb) contained within a Loop.
Step 1: Memory Access Information Collection
Within the function gather_memory_references, every GIMPLE statement of each basic block (bb) in the Loop body that does not belong to a sub-loop is traversed. If the statement stmt is an assignment, the REFERENCE_CLASS_P macro is used to determine whether its left-hand side (lhs) and right-hand side (rhs) involve array memory access. If array memory access occurs, the gather_memory_references_ref function is used to record the memory access information into refs. The data structure is organized by mem_ref_group and mem_ref, as analyzed in Section 3.1.。
refs = gather_memory_references (loop, &no_other_refs, &mem_ref_count);
static struct mem_ref_group *
gather_memory_references (struct loop *loop, bool *no_other_refs, unsigned *ref_count)
{
for (i = 0; i < loop->num_nodes; i++)
{
bb = body[i];
/* loop_father: Innermost loop containing the block. */
if (bb->loop_father != loop)
continue;
for (bsi = gsi_start_bb (bb); !gsi_end_p (bsi); gsi_next (&bsi))
{
Within this process, the function gather_memory_references_ref calls the function analyze_ref to calculate the memory access points base, step, delta. It then calls the function find_or_create_group to store the memory access point mem_ref into mem_ref_group. mem_refs with the same base, step are placed in the same mem_ref_group, otherwise, they are arranged in descending order according to step:
gather_memory_references_ref (struct loop *loop, struct mem_ref_group **refs,
tree ref, bool write_p, gimple *stmt)
...
if (!analyze_ref (loop, &ref, &base, &step, &delta, stmt))
return false;
...
/* Now we know that REF = &BASE + STEP * iter + DELTA, where DELTA and STEP
are integer constants. */
agrp = find_or_create_group (refs, base, step);
record_ref (agrp, stmt, ref, delta, write_p);
/* Finds a group with BASE and STEP in GROUPS, or creates one if it does not
exist. */
static struct mem_ref_group *
find_or_create_group (struct mem_ref_group **groups, tree base, tree step)
/* If step is an integer constant, keep the list of groups sorted
by decreasing step. */
if (int_cst_value ((*groups)->step) < int_cst_value (step))
group = XNEW (struct mem_ref_group);
group->base = base;
group->step = step;
group->refs = NULL;
group->uid = ++last_mem_ref_group_uid;
group->next = *groups;
*groups = group;
return group;
For the function analyze_ref, it calls the function idx_analyze_ref to calculate base, step. It is important to distinguish between the definitions of base, step for affine_iv iv and mem_ref, as annotated below:
static bool
idx_analyze_ref (tree base, tree *index, void *data)
/* To calculate `ibase` and `step`, the terminal function called is `simple_iv_with_niters`, as described below. */
if (!simple_iv (ar_data->loop, loop_containing_stmt (ar_data->stmt),
*index, &iv, true))
return false;
ibase = iv.base;
step = iv.step;
if (TREE_CODE (base) == ARRAY_REF)
{
/* stepsize = sizeof(array[0]) */
stepsize = array_ref_element_size (base);
if (!cst_and_fits_in_hwi (stepsize))
return false;
imult = int_cst_value (stepsize);
/* step = sizeof(a[i]) * r */
step = fold_build2 (MULT_EXPR, sizetype,
fold_convert (sizetype, step),
fold_convert (sizetype, stepsize));
/* delta = sizeof(a[i]) * m */
idelta *= imult;
}
bool
simple_iv_with_niters (struct loop *wrto_loop, struct loop *use_loop,
tree op, affine_iv *iv, tree *iv_niters,
bool allow_nonconstant_step)
ev = analyze_scalar_evolution_in_loop (wrto_loop, use_loop, op,
&folded_casts);
/* In the case of accessing an array with the expression `array[(i + MAX_NUM/2) % MAX_NUM]`, the function would return false, because it is considered to contain a parameter.*/
if (chrec_contains_undetermined (ev)
|| chrec_contains_symbols_defined_in_loop (ev, wrto_loop->num))
return false;
iv->base = ev;
iv->step = build_int_cst (TREE_TYPE (ev), 0);
For the following example, the results of the memory access information collection as printed by gdb show that two memory access points are collected. However, in prune_by_reuse, the first ref->prefetch_mod will be assigned the value 13, which is not equal to PREFETCH_ALL=18446744073709551615. Consequently, the function should_issue_prefetch_p determines not to emit a prefetch:
#include<stdio.h>
#define MAX_NUM 1024*1024
int sum = 0;
int main(){
int num[MAX_NUM];
for (int i=9; i<MAX_NUM; i+=7){
sum += num[i];
sum += num[i+90];
}
return 0;
}
(gdb) set print pretty off
(gdb) p *refs
$26 = {base = 0x7ffff66f2cb0, step = 0x7ffff6727918, refs = 0x1544320, next = 0x0, uid = 1}
(gdb) p *refs->refs
$27 = {stmt = 0x7ffff6716960, mem = 0x7ffff66f27a8, delta = 36, group = 0x16f1c40, prefetch_mod = 1, prefetch_before = 18446744073709551615, reuse_distance = 0, next = 0x154b210, uid = 1, write_p = 0, independent_p = 0, issue_prefetch_p = 0, storent_p = 0}
(gdb) p *refs->refs->next
$28 = {stmt = 0x7ffff6716aa0, mem = 0x7ffff66f27e0, delta = 396, group = 0x16f1c40, prefetch_mod = 1, prefetch_before = 18446744073709551615, reuse_distance = 0, next = 0x0, uid = 2, write_p = 0, independent_p = 0, issue_prefetch_p = 0, storent_p = 0}
For the following example, both memory access points are collected, but they are treated as belonging to different mem_ref_groups. The array base addresses are &array[0] and &array[MAX_NUM-1], respectively, with iteration step sizes of +4 and -4:
#define MAX_NUM 1024*1024
int sum = 0;
int main(){
int num[MAX_NUM];
for (int i=0; i<MAX_NUM; i++){
sum += num[i] + num [MAX_NUM-i];
}
return 0;
}
(gdb) p *refs
$1 = {base = 0x7ffff66d15e8, step = 0x7ffff65c0dc8, refs = 0x154b210, next = 0x16c0bd0, uid = 1}
(gdb) p *refs->refs
$2 = {stmt = 0x7ffff66c0f00, mem = 0x7ffff66d10e0, delta = 0, group = 0x169e9f0, prefetch_mod = 1, prefetch_before = 18446744073709551615, reuse_distance = 0, next = 0x0, uid = 1, write_p = 0, independent_p = 0, issue_prefetch_p = 0, storent_p = 0}
(gdb) p *refs->next
$3 = {base = 0x7ffff66d1620, step = 0x7ffff66d9d40, refs = 0x154b260, next = 0x0, uid = 2}
(gdb) p int_cst_value(refs->step)
$1 = 4
(gdb) p int_cst_value(refs->next->step)
$2 = -4
In the given example, only the first memory access information is collected. This is because the function chrec_contains_undetermined determines that there are parameters within the memory access iterator.
#include<stdio.h>
#define MAX_NUM 1024*1024
int sum = 0;
int main(){
int num[MAX_NUM];
for (int i=9; i<MAX_NUM; i+=7){
sum += num[i];
sum += num[(i+MAX_NUM/2)%MAX_NUM];
}
return 0;
}
(gdb) p *refs
$1 = {base = 0x7ffff66f2cb0, step = 0x7ffff6720c30, refs = 0x154b210, next = 0x0, uid = 1}
(gdb) p *refs->refs
$2 = {stmt = 0x7ffff6716960, mem = 0x7ffff66f27a8, delta = 36, group = 0x15d22a0, prefetch_mod = 1, prefetch_before = 18446744073709551615, reuse_distance = 0, next = 0x0, uid = 1, write_p = 0, independent_p = 0, issue_prefetch_p = 0, storent_p = 0}
Cost Model 2: Estimated Loop Instruction Count vs. Memory Reference Count
If the number of memory references mem_ref_count exceeds the preset value of PREFETCH_MAX_MEM_REFS_PER_LOOP, which is 200, prefetching is considered not cost-effective, and no prefetching is done.
Similarly, if the ratio of ninsns (total instructions in the loop) to mem_ref_count is less than PREFETCH_MAX_MEM_REFS_PER_LOOP, prefetching is also considered not cost-effective, and no prefetching is performed. This step calculates the proportion of memory access instructions to prevent the cost of prefetching instructions from becoming a significant overhead in the execution of the program.
if (!mem_ref_count_reasonable_p (ninsns, mem_ref_count))
goto fail;
Step 2: Reuse Analysis + Locality Analysis
This step is aimed at setting mem_ref->prefetch_mod and mem_ref->prefetch_before, thereby coordinating with the subsequent function should_issue_prefetch_p to control whether prefetching should occur or not.
| Parameter | Meaning |
|---|---|
| prefetch_mod | Prefetch every prefetch_mod iterations, initially set to 1 |
| prefetch_before | Only prefetch in the first prefetch_before iterations (before unrolling)Initial value is PREFETCH_ALL=18446744073709551615 |
/* Step 2: estimate the reuse effects. */
prune_by_reuse (refs);
The calling hierarchy is as follows, performing a depth-first traversal on mem_ref_group and mem_ref:
prune_by_reuse (struct mem_ref_group *groups)
{
for (; groups; groups = groups->next)
prune_group_by_reuse (groups);
}
prune_group_by_reuse (struct mem_ref_group *group)
{
struct mem_ref *ref_pruned;
for (ref_pruned = group->refs; ref_pruned; ref_pruned = ref_pruned->next){
prune_ref_by_reuse (ref_pruned, group->refs);
}
}
prune_ref_by_reuse (struct mem_ref *ref, struct mem_ref *refs)
{
prune_ref_by_self_reuse (ref);
for (prune_by = refs; prune_by; prune_by = prune_by->next){
if (prune_by != ref)
prune_ref_by_group_reuse (ref, prune_by, before);
}
}
The function prune_ref_by_self_reuse first preprocesses based on mem_ref->step, and then sets prefetch_mod and prefetch_before according to the conditions outlined in the following table.
| case | 设置 |
|---|---|
| mem_ref->step is not constant | no modification for prefetch_mod or prefetch_before, no further calculation |
| mem_ref->step < 0 | mem_ref->step = -mem_ref->step backward = true |
| mem_ref->step = 0 | prefetch_before = 1, no further calculation |
| (backward && HAVE_BACKWARD_PREFETCH) || (!backward && HAVE_FORWARD_PREFETCH) |
prefetch_before = 1, no further calculation |
| else | prefetch_mod = PREFETCH_BLOCK / step |
The function prune_ref_by_group_reuse also performs preprocessing and then sets prefetch_mod.
let delta=ref->delta - by->delta,step=ref->group->step。
| case | case-case | setting |
|---|---|---|
| delta = 0 | —— | prefetch_before = 0 |
| step != 0 | in men_ref_group, by goes after ref | —— |
| ref->delta/PREFETCH_BLOCK != by->delta/PREFETCH_BLOCK |
—— | |
| else | prefetch_before = 0 | |
| step < 0 | delta < 0 | —— |
| else | let step be positive, go on execution | |
| step > 0 | delta < 0 | —— |
| go on execution-case | setting |
|---|---|
| step < PREFETCH_BLOCK | prefetch_before = (hit_from - delta_r + step - 1) / step |
| step > PREFETCH_BLOCK | prefetch_before = delta / step |
Assuming a cache line length of 64 bytes and the size of a char is 1 byte, without support for hardware prefetching, analyze the following example.:
char *a;
for (i = 0; i < max; i++)
{
a[255] = ...; (0) /* PREFETCH_BEFORE 1 */
a[i] = ...; (1) /* PREFETCH_BEFORE 64 */
a[i + 64] = ...; (2)
a[16*i] = ...; (3)
a[187*i] = ...; (4)
a[187*i + 50] = ...; (5)
}
| No | Description(PREFETCH_BEFORE default value is PREFETCH_ALL=18446744073709551615) |
|---|---|
| 0 | PREFETCH_BEFORE 1 |
| 1 | PREFETCH_BEFORE 64,because (2) accesses the memory location of (1) 64 iterations in advance. PREFETCH_MOD 64,considering the size of Cache line |
| 2 | PREFETCH_MOD 64 |
| 3 | PREFETCH_MOD 4 |
| 4 | PREFETCH_MOD is set to 1. PREFETCH_BEFORE is not set here because the probability of (5) accessing the memory location of (4) is only 7/32. |
| 5 | PREFETCH_MOD 1 |
After the reuse analysis, the function nothing_to_prefetch calls should_issue_prefetch_p to determine whether each memory access point needs prefetching. Only those memory access points for which prefetch_before == PREFETCH_ALL and storent_p == false are considered to require prefetching.
static bool
nothing_to_prefetch_p (struct mem_ref_group *groups)
{
struct mem_ref *ref;
for (; groups; groups = groups->next)
for (ref = groups->refs; ref; ref = ref->next)
if (should_issue_prefetch_p (ref))
return false;
return true;
}
The function determine_loop_nest_reuse performs a locality analysis to determine the distance before each reference in the REFS of a LOOP’s loop nest is reused for the first time. If there are no other memory references in the loop, NO_OTHER_REFS is set to true. If the analysis fails, it returns false.
Step Three: Deciding Whether to Perform Loop Unrolling
unroll_factor is the loop unrolling factor. The function determine_unroll_factor traverses each memory access information recorded in refs, calculating the least common multiple (LCM) of all ref->prefetch_mod values. The specific algorithm used is the Euclidean algorithm, also known as the division algorithm, to find the greatest common divisor (GCD) of two numbers, and then dividing the product of the two numbers by their GCD to obtain the LCM. If the loop body has a low iteration count, loop unrolling is not performed.
After determining the number of loop unrollings, prefetch_count is used to tally the number of prefetches in the loop body. If the prefetch count is zero, the subsequent algorithms are not executed.
/* Step 3: determine unroll factor. */
unroll_factor = determine_unroll_factor (loop, refs, ninsns, &desc, est_niter);
/* Estimate prefetch count for the unrolled loop. */
prefetch_count = estimate_prefetch_count (refs, unroll_factor);
if (prefetch_count == 0)
goto fail;
Taking the loop body (A) as an example, it has two memory access points. Suppose the prefetch_mod of the first memory access point is 2, and the prefetch_mod of the second memory access point is 3. Then, the unroll_factor would be 6, meaning the loop is unrolled six times to become (B). Originally, for the first memory access point, a prefetch is inserted every two iterations; therefore, in (B), three prefetches are inserted in one iteration. Similarly, two prefetches are inserted for the second memory access point.
The core code in the function estimate_prefetch_count that corresponds to this process is shown in (C), which performs a ceiling operation.
(A)
for (int i=0; i<MAX_NUM; i++)
...
_array[i]
...
array[(i+89)mod MAX_NUM]
(B)
for (int i=0; i<MAX_NUM; i+=6)
...
_array[i] ... array[(i+89)mod MAX_NUM]
...
_array[i+1] ... array[(i+90)mod MAX_NUM]
...
_array[i+2] ... array[(i+91)mod MAX_NUM]
...
_array[i+3] ... array[(i+92)mod MAX_NUM]
...
_array[i+4] ... array[(i+93)mod MAX_NUM]
...
_array[i+5] ... array[(i+94)mod MAX_NUM]
(C)
n_prefetches = ((unroll_factor + ref->prefetch_mod - 1)
/ ref->prefetch_mod);
Cost Model 3: Instruction Count to Prefetch Count Ratio
When the ratio of the total number of instructions after loop unrolling (unroll_factor * ninsns) to the number of prefetch instructions (prefetch_count) is too low, prefetching is likely to lead to a performance degradation. Specifically, having too many prefetch instructions in the loop can diminish the performance of the Instruction Cache (I-cache).
/* Prefetching is not likely to be profitable if the instruction to prefetch
ratio is too small. */
if (insn_to_prefetch_ratio_too_small_p (ninsns, prefetch_count, unroll_factor))
goto fail;
mark_nontemporal_stores (loop, refs);
insn_to_prefetch_ratio_too_small_p()
insn_to_prefetch_ratio = unroll_factor * ninsns / prefetch_count;
Step Four: Deciding on the Prefetch Targets
The function schedule_prefetches iterates over refs, deciding whether to reserve prefetch resources for a memory access point.
/* Step 4: what to prefetch? */
if (!schedule_prefetches (refs, unroll_factor, ahead))
goto fail;
Computers have limited prefetch resources; at any given moment, at most SIMULTANEOUS_PREFETCHES prefetches can be issued. This resource limitation is referred to as prefetch slots, based on the variable remaining_prefetch_slots in the function schedule_prefetches.
The following excerpted code segment calculates the total number of prefetch slots occupied by each memory access point ref:
schedule_prefetches (struct mem_ref_group *groups, unsigned unroll_factor, unsigned ahead)
/* slots_per_prefetch = ahead/unroll_factor round up */
slots_per_prefetch = (ahead + unroll_factor / 2) / unroll_factor;
/* n_prefetches = unroll_factor/ref->prefetch_mod round up */
n_prefetches = ((unroll_factor + ref->prefetch_mod - 1) / ref->prefetch_mod);
prefetch_slots = n_prefetches * slots_per_prefetch;
A single prefetch operation takes ahead cycles, and after loop unrolling, a single prefetch takes ahead/unroll_factor cycles. If we stipulate that one prefetch occupies one prefetch slot per cycle, then slots_pre_prefetch represents the number of prefetch slots occupied by a single prefetch. Based on the previous section, after loop unrolling, there are unroll_factor/prefetch_mod instances of a memory access point per cycle. Thus, the total number of prefetch slots occupied by each memory access point is n_prefetches * slots_per_prefetch.
if (2 * remaining_prefetch_slots < prefetch_slots)
continue;
ref->issue_prefetch_p = true;
if (remaining_prefetch_slots <= prefetch_slots)
return true;
remaining_prefetch_slots -= prefetch_slots;
any = true;
}
return any;
When the total number of prefetch slots occupied by a ref falls within the range (remaining_prefetch_slots*2, +∞), prefetch resources are not allocated, and the process continues to the next memory access points.
When the total number of prefetch slots occupied by a ref is within the range [0, remaining_prefetch_slots*2], the use of prefetch slot resources is allowed, and the flag issue_prefetch_p is set to true. This flag will be referenced in step six.
When the total number of prefetch slots occupied by a ref falls within the range [remaining_prefetch_slots, remaining_prefetch_slots*2], meaning the remaining prefetch slots will be exhausted by the current memory access point, no prefetch resources will be allocated to subsequent memory access points.
The allocation of prefetch slots implies a priority, with GCC considering memory access points with a larger array element step step more likely to cause cache misses. The memory access information collected by the function gather_memory_references is allocated in descending order of the array element step step, thus memory accesses with a larger step are more likely to be allocated prefetch slot resources.
In the following example, (A) is the loop before unrolling, and (B) is the loop after unrolling, with parameters for each memory access point annotated.
(A)
for (int i=0; i<MAX_NUM; i++)
...
_array[i] /* mod=2, step=8 */
...
array[(i+89)mod MAX_NUM] /* mod=3, step=4 */
...
arr[i/2] /* mod=6, step=2 */
(B)
/* ahead=10, SIMULTANEOUS_PREFETCHES=8 */
for (int i=0; i<MAX_NUM; i++) /* unroll_factor=6 */
/* slots_per_prefetch = (10+6/2)/6 = 2 */
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
...
_array[i] ... array[(i+89)mod MAX_NUM] ... arr[i/2]
/*
* _array: n_prefetches = 3, prefetch_slots = 6
* array: n_prefetches = 2, prefetch_slots = 4
* arr: n_prefetches = 1, prefetch_slots = 2
*/
The function schedule_prefetches will allocate prefetch slots in descending order of step size, assigning 6 prefetch slots to _array and 2 prefetch slots to array.
Step Five: Loop Unrolling
The function tree_unroll_loop first redefines the SSA join-flow PHI functions, then removes the excess loop->latch after loop unrolling, and adjusts the probabilities of goto statements within the loop body. This adjustment ensures that the variables within the loop body conform again to the SSA properties.
/* Step 5: unroll the loop. TODO -- peeling of first and last few
iterations so that we do not issue superfluous prefetches. */
if (unroll_factor != 1)
{
tree_unroll_loop (loop, unroll_factor,
single_dom_exit (loop), &desc);
unrolled = true;
}
Below, the changes to Basic Block 4 before and after loop unrolling are listed.
/* loop-in-loop.c.165t.cunroll */
<bb 4> [local count: 1063004407]:
# j_25 = PHI <0(3), j_14(8)>
# sum_lsm.2_8 = PHI <sum_lsm.2_7(3), _6(8)>
# ivtmp_12 = PHI <1048576(3), ivtmp_33(8)>
_4 = num[j_25];
_6 = _4 + sum_lsm.2_8;
j_14 = j_25 + 1;
ivtmp_33 = ivtmp_12 - 1;
if (ivtmp_33 != 0)
goto <bb 8>; [98.99%]
else
goto <bb 5>; [1.01%]
/* loop-in-loop.c.167t.aprefetch */
547:<bb 4> [local count: 10737418]:
548: # j_25 = PHI <0(3), j_287(108)>
549: # sum_lsm.2_8 = PHI <sum_lsm.2_7(3), _286(108)>
550: # ivtmp_12 = PHI <1048576(3), ivtmp_288(108)>
551: # ivtmp_289 = PHI <1048575(3), ivtmp_290(108)>
552: _291 = &num[j_25];
553: _292 = _291 + 272;
554: __builtin_prefetch (_292, 0, 0);
555: _4 = num[j_25];
556: _6 = _4 + sum_lsm.2_8;
557: j_14 = j_25 + 1;
558: ivtmp_33 = ivtmp_12 - 1;
559: _45 = num[j_14];
560: _46 = _6 + _45;
......
......
681: j_287 = j_279 + 1;
682: ivtmp_288 = ivtmp_280 + 4294967295;
683: ivtmp_290 = ivtmp_289 - 32;
684: if (ivtmp_290 > 31)
685: goto <bb 108>; [83.33%]
686: else
687: goto <bb 13>; [16.67%]
Step Six: Issuing Prefetches
The function issue_prefetches issues prefetch instructions for memory access points that have been allocated prefetch slot resources. The function issue_prefetch_ref accumulates base, step, delta, where delta includes not only the array offset but also a newly added prefetch lookahead distance. Finally, the function inserts prefetch GIMPLE statements into the current GIMPLE sequence, as seen in the previous section’s loop-in-loop.c.165t.cunroll.
/* Step 6: issue the prefetches. */
issue_prefetches (refs, unroll_factor, ahead);
static void
issue_prefetches (struct mem_ref_group *groups,
unsigned unroll_factor, unsigned ahead)
{
struct mem_ref *ref;
for (; groups; groups = groups->next)
for (ref = groups->refs; ref; ref = ref->next)
if (ref->issue_prefetch_p)
issue_prefetch_ref (ref, unroll_factor, ahead);
}
static void
issue_prefetch_ref (struct mem_ref *ref, unsigned unroll_factor, unsigned ahead)
for (ap = 0; ap < n_prefetches; ap++)
{
if (cst_and_fits_in_hwi (ref->group->step))
{
/* Determine the address to prefetch. */
delta = (ahead + ap * ref->prefetch_mod) *
int_cst_value (ref->group->step);
addr = fold_build_pointer_plus_hwi (addr_base, delta);
addr = force_gimple_operand_gsi (&bsi, unshare_expr (addr), true,
NULL, true, GSI_SAME_STMT);
}
/* Create the prefetch instruction. */
prefetch = gimple_build_call (builtin_decl_explicit (BUILT_IN_PREFETCH),
3, addr, write_p, local);
gsi_insert_before (&bsi, prefetch, GSI_SAME_STMT);
}
The process file to focus on when debugging prefetch instructions is described in section 1.2.
3.2.4 Design Thoughts for sum.c: Excluding Cases Where Memory Accesses are Collected but Not Prefetched
(TODO): Currently, there are few encountered examples. More accumulation is needed.
In cases where prefetch_before is set to a value other than PREFETCH_ALL by the prune reuse analysis, such as for array[i] and array[i+90], where the former has prefetch_mod=13 and the iterator is i+=7, no resources are allocated by schedule_prefetches.
The function chrec_contains_undetermined determines the presence of parameters in the memory access iterator, as in array[(i+MAX_NUM/2)%MAX_NUM]. This might be due to issues related to rounding when dealing with odd and even numbers.
4. Prefetch Optimization Performance Analysis
The table is available on the intranet (TODO).
6A, 6B, int, fp, see specific settings in the table header.
4.1 Evaluation Level Settings and Corresponding Options
4.2 SPEC2006 Evaluation Results
4.3 SPEC2017 Evaluation Results
4.4 Evaluation Results Analysis
2014 paper
Appendix A
GCC currently provides support for prefetching, and the features offered, in descending order from bottom to top, are as follows:
- A generic prefetch RTL pattern.
- Target-specific support for several targets.
- A
__builtin_prefetchfunction that does nothing on targets that do not support prefetch or for which prefetch support has not yet been added to GCC.- An optimization enabled by
-fprefetch-loop-arraysthat prefetches arrays used in loops.
The -O2 optimization level automatically enables -fprefetch-loop-arrays, which instructs the compiler to invoke prefetch optimization passes. These passes insert the built-in function __builtin_prefetch() into the program’s assembly code. During the conversion from GIMPLE trees to RTL trees, the built-in function is translated into prefetch instructions based on backend instruction templates. These backend instruction templates may be generic RTL templates provided by GCC or RTL templates provided by the target machine.
xxGCC follows a similar hierarchical structure and designs first-level prefetching, second-level prefetching, and third-level prefetching. The various levels involve the following files, with suffixes corresponding to macros in xxGCC1126:
First-level prefetching (ZCL20220706_pf)
omitted
Second-level prefetching (ZCL20220711_pf_sc)
omitted
Third-level prefetching (ZCL20220715_pf_tc)
omitted
Multi-level prefetching (ZCL20220715_pf_multi_ctrl)
omitted
Appendix B
Located at the top of gcc/tree-ssa-loop-prefetch.c, this section introduces the process of prefetching algorithms, along with three cost models. It provides a comprehensive example specifically addressing prefetch_mod.
/* This pass inserts prefetch instructions to optimize cache usage during
accesses to arrays in loops. It processes loops sequentially and:
1) Gathers all memory references in the single loop.
2) For each of the references it decides when it is profitable to prefetch
it. To do it, we evaluate the reuse among the accesses, and determines
two values: PREFETCH_BEFORE (meaning that it only makes sense to do
prefetching in the first PREFETCH_BEFORE iterations of the loop) and
PREFETCH_MOD (meaning that it only makes sense to prefetch in the
iterations of the loop that are zero modulo PREFETCH_MOD). For example
(assuming cache line size is 64 bytes, char has size 1 byte and there
is no hardware sequential prefetch):
char *a;
for (i = 0; i < max; i++)
{
a[255] = ...; (0)
a[i] = ...; (1)
a[i + 64] = ...; (2)
a[16*i] = ...; (3)
a[187*i] = ...; (4)
a[187*i + 50] = ...; (5)
}
(0) obviously has PREFETCH_BEFORE 1
(1) has PREFETCH_BEFORE 64, since (2) accesses the same memory
location 64 iterations before it, and PREFETCH_MOD 64 (since
it hits the same cache line otherwise).
(2) has PREFETCH_MOD 64
(3) has PREFETCH_MOD 4
(4) has PREFETCH_MOD 1. We do not set PREFETCH_BEFORE here, since
the cache line accessed by (5) is the same with probability only
7/32.
(5) has PREFETCH_MOD 1 as well.
Additionally, we use data dependence analysis to determine for each
reference the distance till the first reuse; this information is used
to determine the temporality of the issued prefetch instruction.
3) We determine how much ahead we need to prefetch. The number of
iterations needed is time to fetch / time spent in one iteration of
the loop. The problem is that we do not know either of these values,
so we just make a heuristic guess based on a magic (possibly)
target-specific constant and size of the loop.
4) Determine which of the references we prefetch. We take into account
that there is a maximum number of simultaneous prefetches (provided
by machine description). We prefetch as many prefetches as possible
while still within this bound (starting with those with lowest
prefetch_mod, since they are responsible for most of the cache
misses).
5) We unroll and peel loops so that we are able to satisfy PREFETCH_MOD
and PREFETCH_BEFORE requirements (within some bounds), and to avoid
prefetching nonaccessed memory.
TODO -- actually implement peeling.
6) We actually emit the prefetch instructions. ??? Perhaps emit the
prefetch instructions with guards in cases where 5) was not sufficient
to satisfy the constraints?
A cost model is implemented to determine whether or not prefetching is
profitable for a given loop. The cost model has three heuristics:
1. Function trip_count_to_ahead_ratio_too_small_p implements a
heuristic that determines whether or not the loop has too few
iterations (compared to ahead). Prefetching is not likely to be
beneficial if the trip count to ahead ratio is below a certain
minimum.
2. Function mem_ref_count_reasonable_p implements a heuristic that
determines whether the given loop has enough CPU ops that can be
overlapped with cache missing memory ops. If not, the loop
won't benefit from prefetching. In the implementation,
prefetching is not considered beneficial if the ratio between
the instruction count and the mem ref count is below a certain
minimum.
3. Function insn_to_prefetch_ratio_too_small_p implements a
heuristic that disables prefetching in a loop if the prefetching
cost is above a certain limit. The relative prefetching cost is
estimated by taking the ratio between the prefetch count and the
total intruction count (this models the I-cache cost).
The limits used in these heuristics are defined as parameters with
reasonable default values. Machine-specific default values will be
added later.
-
董钰山,李春江,徐颖.GCC编译器中循环数组预取优化的实现及效果[J].计算机工程与应用,2016,52(6):19-25 ↩ ↩2 ↩3
-
Novillo, D. (2003). Tree SSA A New Optimization Infrastructure for GCC. Proceedings of the GCC Developer Summit, Figure 1, 181–193. ↩
-
Mowry, T. C., Lam, M. S., & Gupta, A. (1992). Design and evaluation of a compiler algorithm for prefetching. International Conference on Architectural Support for Programming Languages and Operating Systems - ASPLOS, 27(9), 62–73. https://doi.org/10.1145/143371.143488 ↩